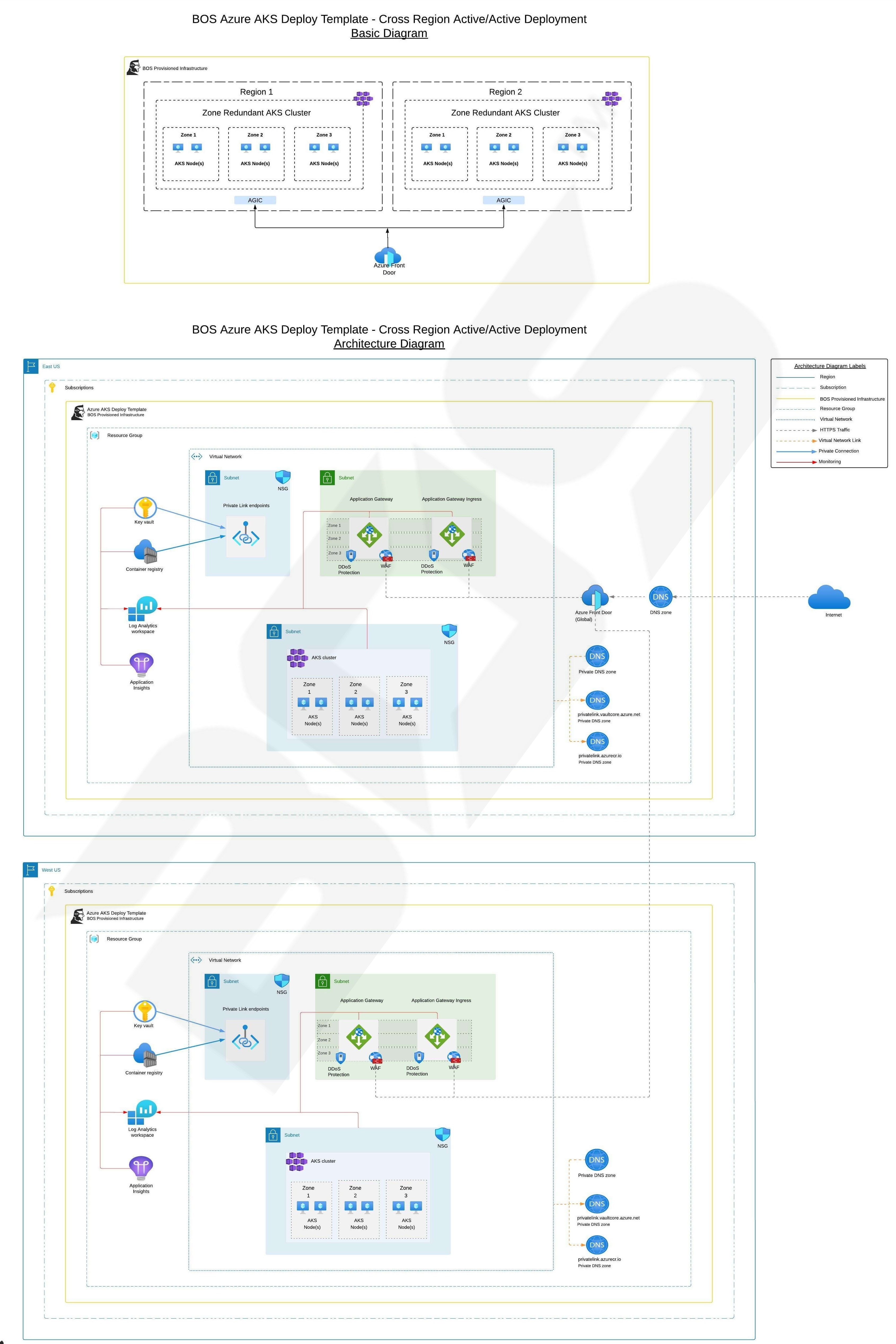
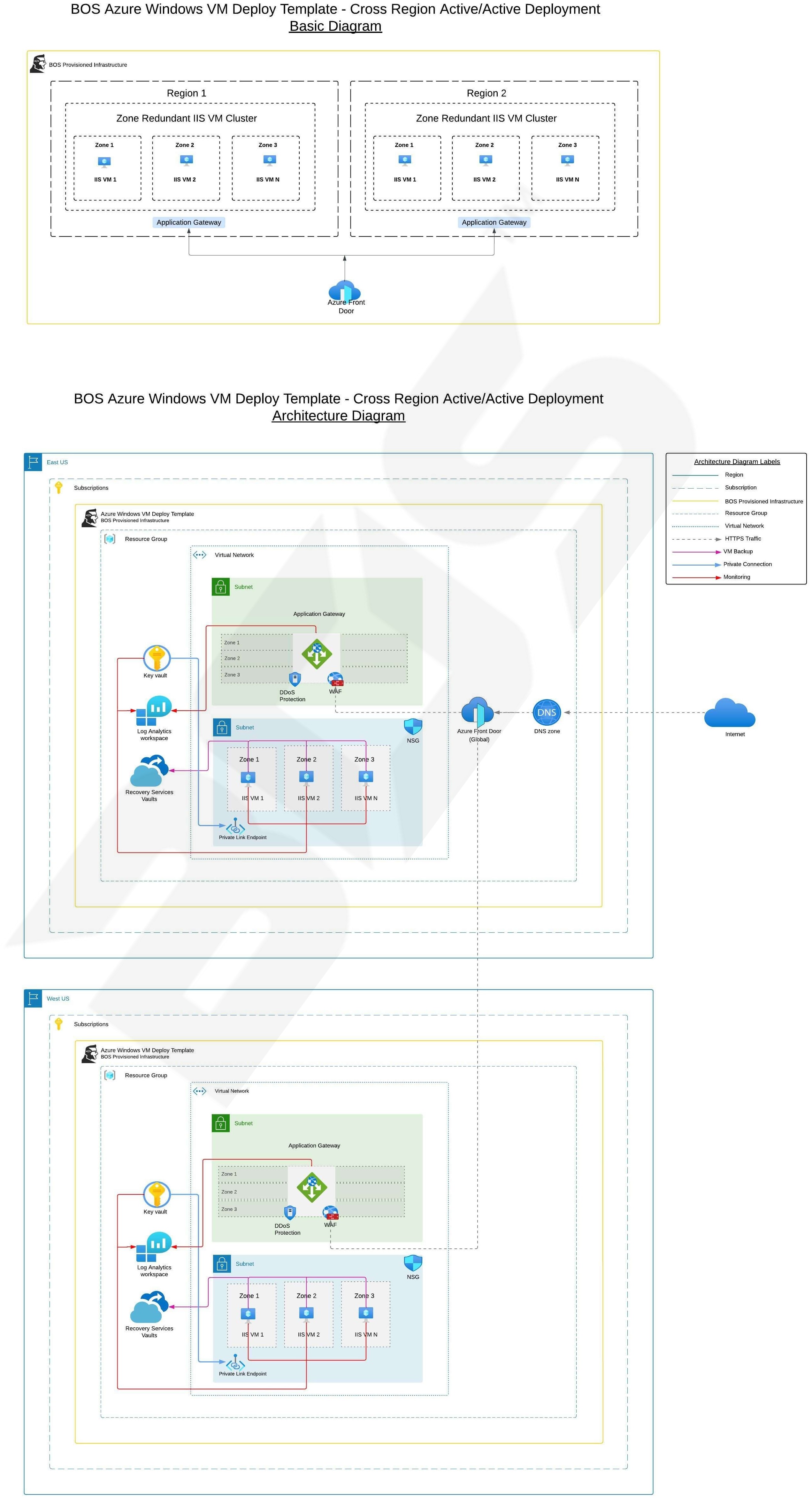
Introduction
Overview
BOS offers users versatile solutions for achieving High Availability (HA) and Disaster Recovery (DR) through our environment templates and pipeline templates. Our templates create resources that are zone redundant, ensuring robust High Availability. This approach empowers users to efficiently manage infrastructure, deploy applications, and seamlessly transition between regions, especially in the face of region-wide failures. BOS facilitates cost optimization by eliminating the need for a constantly active-active setup. For users with specific requirements, customized active-active setups can also supported.The Need for HA/DR
In today's interconnected and data-driven world, downtime, data loss, or system outages can have severe consequences, including financial losses, damage to reputation, and legal liabilities. Our reliance on digital systems and the continuous flow of information makes it imperative to address the following key challenges:
1. System Reliability
Our organization depends on a wide range of systems and applications to conduct daily operations, serve customers, and support decision-making. Any interruption or failure in these systems can result in productivity losses and customer dissatisfaction.
2. Data Protection
Data is one of our most valuable assets, and its loss or corruption can have far-reaching implications. Ensuring data integrity and availability is paramount, especially in an era where data breaches and cyberattacks are on the rise.
3. Compliance and Regulations
We operate in an environment governed by various regulatory requirements. Compliance with data protection and retention standards is mandatory, and HA/DR measures help us meet these obligations.
4. Business Continuity
In the event of natural disasters, hardware failures, or other unforeseen incidents, we must be prepared to maintain essential operations without significant disruption. HA/DR ensures that we can recover swiftly and continue serving our customers.
Goals of HA/DR
Our HA/DR strategy aims to achieve the following key objectives:
Minimize Downtime: Reduce system downtime to a minimum, ensuring that our critical services are available to users without interruption.
Data Resilience: Protect our data from loss, corruption, or unauthorized access, ensuring data is consistently available when needed.
Rapid Recovery: Enable quick recovery of systems and data in the event of failures or disasters, allowing us to restore normal operations swiftly.
Compliance: Ensure compliance with legal and regulatory requirements related to data protection, retention, and disaster recovery.
Business Confidence: Build trust with our stakeholders, customers, and partners by demonstrating our commitment to operational continuity and data security.
Disaster Recovery (DR) Components
Infrastructure Creation Time:
Approximate Time: 30-40 minutes
During the initial phase of Disaster Recovery, it takes approximately 30-40 minutes to create new infrastructure in a different region. This period constitutes the downtime when the new infrastructure is being provisioned but is not yet ready to handle traffic.
DNS Propagation Time:
Approximate Time: 60 minutes
DNS resolvers that previously cached the old IP address will retain it for up to 60 minutes before checking for updates. The Time-to-Live (TTL) is set to the default 60 minutes. Health check endpoints are employed to identify the completion of DNS propagation.
Pipeline Execution Time:
Approximate Time: 5-6 minutes for each pipeline
To deploy applications to the new infrastructure in the designated region, each pipeline takes 5-6 minutes to execute.
Total Estimated Downtime: The total estimated downtime is calculated as the sum of the Infrastructure Creation Time, DNS Propagation Time, and Application Deployment Time.
Total Estimated Downtime = Infrastructure Creation Time + DNS Propagation Time + Application Deployment Time
30 minutes + 60 minutes + 60 minutes = 150 minutes = 2.30hrs ~ 3hrs.
This estimation provides a comprehensive understanding of the downtime associated with the Disaster Recovery process. It is crucial for planning and managing expectations during the transition to ensure a smooth and efficient recovery of services in a new region.
Steps for Disaster Recovery (DR) Implementation
Failover Procedure
Follow these steps to implement Disaster Recovery using BOS:
Create another Environment in a Different Region: Initiate Disaster Recovery by creating a new environment in a distinct region using the same Environment Template.
Re-Run the Pipeline Template for the Different Region: Swiftly transition to the new environment in the different region by re-running the pipeline template, ensuring seamless business continuity.
Perform Thorough Verification of the Application URL: Conduct a comprehensive verification of the application URL in the newly created environment to guarantee a successful and functional deployment.
Cost Savings and Customization
Our approach not only ensures High Availability through zone-redundant resources but also provides users with the flexibility to adapt their infrastructure as needed. This results in efficient resource management and cost optimization, eliminating the necessity for a continuous active-active setup unless explicitly required.
By leveraging BOS environment templates and pipeline templates, users can confidently navigate Disaster Recovery scenarios, maintaining application resilience and minimizing downtime in the face of unforeseen challenges.
Below are architecture diagrams for customizable cross region active-active setups which BOS can also support.